水电工幻想
官中步兵版,dlc最新中文
润色版下载
📦 游戏说明
水电工幻想角色扩展 DLC 第二弹!免费畅享全新内容!终于——它来啦!
感谢大家如此耐心的等待。今天,我们终于要发布《水电工幻想》的第二款 DLC 啦
相信不少朋友早就猜出剪影中的角色是谁了吧?
答案就是……公会接待员与商店老板娘
两位新角色的解锁条件:
腐化所有女性角色。
将双生龙姐妹带回家。
至于老板娘,你需要购买她所有的物品(消耗品除外)。

📸 操作秘籍
水电工幻想 自由接案的辣个男人-水电工又来啦!!
某天,他跟往常一样接到了委托,出发前往客户家。
就在他修好了马桶,按下冲水测试时,马桶发出了光芒,将他吸了进去。
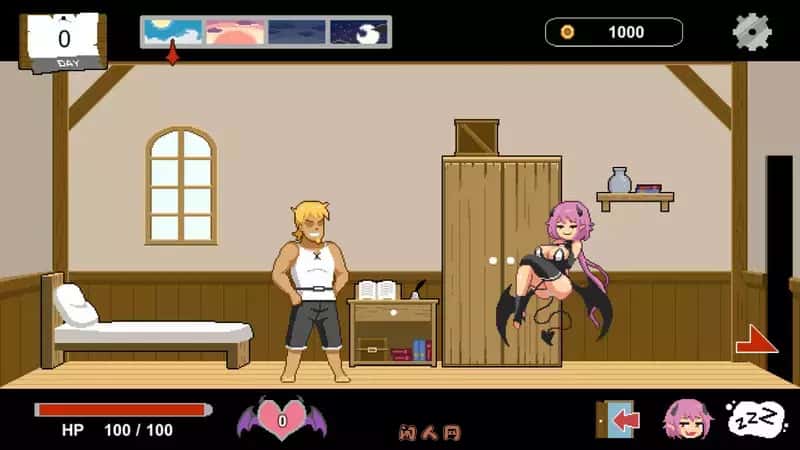
当再次睁开眼睛时,已身处异世界的村庄内。
“终于来了啊……”一旁的女子迎面走来,并对他说:“传说中的工具人……就是你吗?”
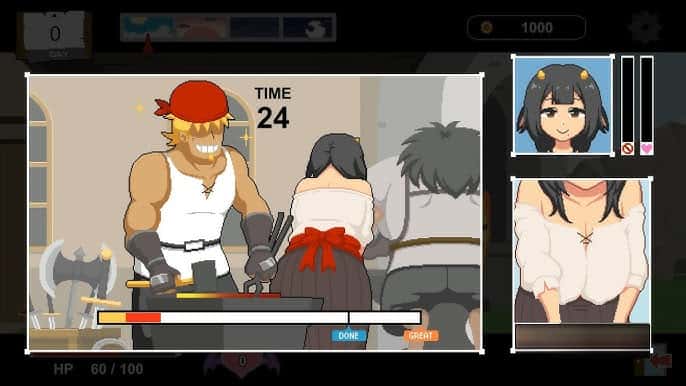
主人公在异世界中也必须打着各种零工来维持生计,在铁匠铺帮忙打铁、酒馆中当店小二、

教会里帮修女们整理书架……等等。甚至还必须陪伴冒险者外出打怪?

在酒吧帮猫娘打工,同时一边瑟瑟
不会打斗只好帮忙坦怪?
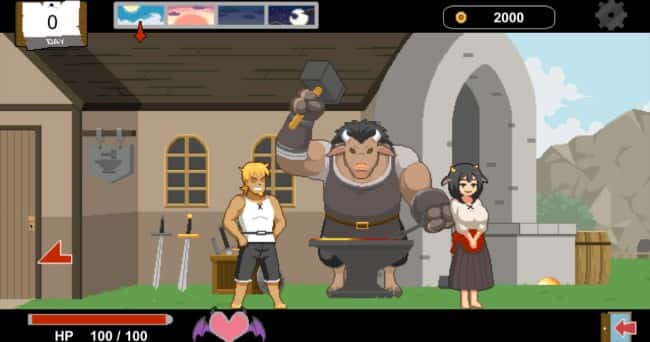
游戏中与各个女主角都有不同且独立的剧情、
工作小游戏(骚扰)、H场景、以及大张CG图。好感度达到一定程度后,还会开启特殊的堕落模式
游戏截图
🔩 润色版下载水电工幻想
游戏已准备好,点击下方按钮开始下载。
下载